0
1
2
3
4
BREAK DETR
My Projects
Hover to expand
Click to explore

Understanding Website Sentiment Analysis

Understanding Website Sentiment Analysis
Engaging frontend using keyframes and typewriting, with eventual sentiment analysis and AWS lambda implementation.
AI Summarizer for Clinical Settings
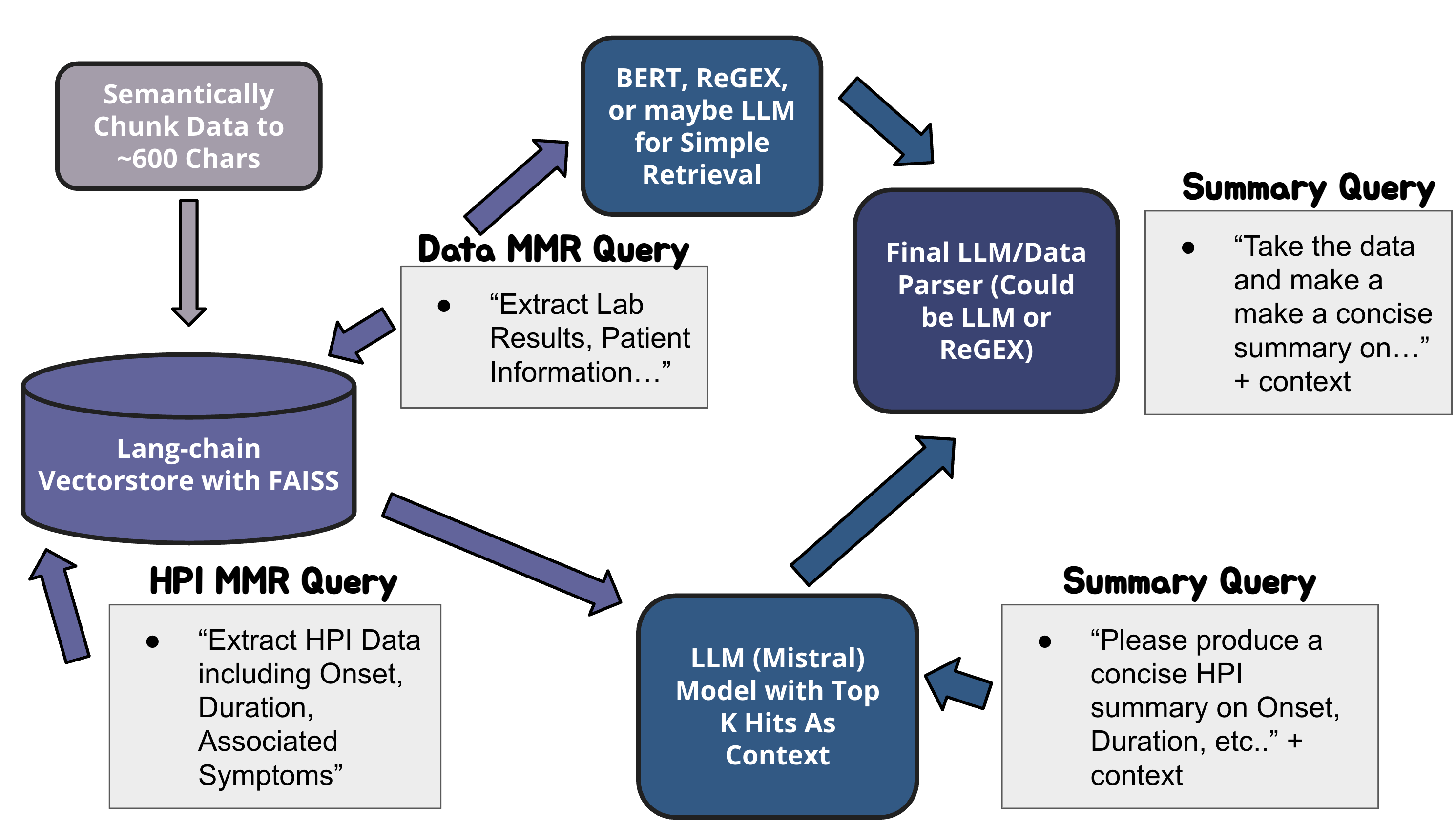
AI Summarizer for Clinical Settings
Using vectorstores, maximal marginal relevance, and GPT OSS to summarize patient (MIMIC) notes for clinical settings. Access the jupyter notebook.
Improved Linkedin Matching Algorithm for Startups
python
from langchain_classic.docstore.document import Document
from typing import List, str, float, Any, int, Dict
from information import USER
from huggingface_hub import InferenceClient
HF_API_TOKEN = ""
client = InferenceClient(token=HF_API_TOKEN)
HF_MODELS = {
'embeddings': 'sentence-transformers/all-MiniLM-l6-v2',
'summary': 'openai/gpt-oss-20b'
}
PROFILES = []
N = len(PROFILES)
def call_huggingface_api(model_name: str, inputs: Any, model_type: str = 'sentiment'):
if model_type == 'embeddings':
results = client.feature_extraction(text=inputs, model=model_name)
return results
else:
results = client.chat.completions.create(
model=model_name,
messages=[
{
"role": "user",
"content": inputs
}
],
)
result = results.choices[0].message
return result['content']
from langchain_core.embeddings import Embeddings
class CustomAPIEmbeddings(Embeddings): #inherits from embeddings class
def embed_documents(self, texts: List[str]) -> List[List[float]]:
return call_huggingface_api(HF_MODELS['embeddings'], texts, model_type='embeddings')
def embed_query(self, text: str) -> List[float]:
return call_huggingface_api(HF_MODELS['embeddings'], text, model_type='embeddings')
def sortBuckets(profiles: List[Dict]):
# every document has metadata = Name
names = {}
ages = [] # documents = string of "college", "early career", "mid career"
locations = [] # documents = string of city name
disciplines = [] # documents = string of career area (computer science, business strategy, investment banking, medical research)
about_projs = [] # documents = the whole about section and projects
work_exps = [] # documents = all work experience + current job
db = {} # a dictionary of a name to another dictionary lol
for i, p in enumerate(profiles):
names[p['name']] = 0
ages.append(Document(
page_content = p['age'],
metadata={'name' : p['name']}
))
locations.append(Document(
page_content = p['location'],
metadata={'name' : p['name']}
))
disciplines.append(Document(
page_content = p['discpline'],
metadata={'name' : p['name']}
))
about_proj = "
".join([p['about'], p['projects']]) # the join method expects a string or tuple
about_projs.append(Document(
page_content = about_proj,
metadata={'name' : p['name']}
))
work_exps.append(Document(
page_content = p['work_exp'],
metadata={'name': p['name']}
))
db[p['name']] = p
return names, ages, locations, disciplines, about_projs, work_exps
names, ages, locations, disciplines, about_projs, work_exps = sortBuckets(PROFILES)
USER_PROF = USER
USER_STACK = ""
for key, value in USER_PROF.items():
USER_STACK = USER_STACK + "
" + value
def extract_keywords(profile: str, k: int = 5):
import yake
"""Campos, R., Mangaravite, V., Pasquali, A., Jatowt, A., Jorge, A., Nunes, C. and Jatowt, A. (2020). YAKE! Keyword Extraction from Single Documents using Multiple Local Features. In Information Sciences Journal. Elsevier, Vol 509, pp 257-289. pdf"""
kw_extractor = yake.KeywordExtractor(
lan="en",
n=3,
dedupLim=0.9,
dedupFunc='seqm', # dedup function which I kinda want to research
windowsSize=1, # context window size
top=k,
features=None
)
keywords = kw_extractor(profile)
keywords_str = "Keywords: " + keywords[0][0]
i = 1
while i < len(keywords):
keywords_str = keywords_str + ", " + keywords[i][0]
return keywords, keywords_str
keywords, keywords_str = extract_keywords(USER_STACK)
# Work for Future Me
# - create an algorithm using the google geo api that uses the longitude
# - use the haversine formula to calculate the distance
# - penalize large distances using the negative natural log
# - use a data-base of cities to classify them by population size, 0 = small, 1 = medium, 2 = large
# - use another data-base of cities to classify them by city style, so like country side, coast, big city
# ----------------------------------------------------
def process_locations(names: List[Dict], locations: List[Document]):
return
def process_disciplines():
return
# ----------------------------------------------------
def mmr_retrieval(names: Dict, about_projs: List[Document], work_exps: List[Document], user: Dict, k: int = 5, fetch_k: int = 20, lm: int = 0.7):
from langchain_community.vectorstores import FAISS
hf_embedder = CustomAPIEmbeddings()
about_vectorstore = FAISS.from_documents(
documents=about_projs,
embedding=hf_embedder
)
about_res = about_vectorstore.max_marginal_relevance_search(
query=user['about'] + user['projects'],
k=k if k < N else N,
fetch_k=fetch_k if fetch_k < N else N,
lambda_mult=lm
)
work_vectorstore = FAISS.from_documents(
documents=work_exps,
embedding=hf_embedder
)
work_res = work_vectorstore.max_marginal_relevance_search(
query=user['work_exp'],
k=k if k < N else N,
fetch_k=fetch_k if fetch_k < N else N,
lambda_mult=lm
)
for i, about in enumerate(about_res):
names[about.metadata['name']] = names[about.metadata['name']] + 1
for i, work in enumerate(work_res):
names[work.metadata['name']] = names[work.metadata['name']] + 1
return names, about_res, work_res
import heapq # a min heap of pairs
def semantic_relevance(top_matches: List[str], user: str, keyword_str: str ):
prompt = f"""Assign a score to each of the three profiles based on if they would be a great match to the user profile.
Use the keywords in decision making.
Keywords: {keyword_str}
Profile 1:
{top_matches[0]}
Profile 2:
{top_matches[1]}
Profile 3:
{top_matches[2]}
User Profile:
{user}
Provide:
1. A matching score for profile 1, profile 2, and profile 3.
2. Provide a reason for each score.
"""
return call_huggingface_api(HF_MODELS['summary'], prompt, model_type="summary")
Improved Linkedin Matching Algorithm for Startups
Thought experiment for improved matching algorithm, using maximal marginal relevance, sentence-transformers, openai/GPT, and haversine formula.
Fashion Chatbot using Data Structures and Algorithms

Fashion Chatbot using Data Structures and Algorithms
Improved algorithm using hash maps and mersenne twisters, and prefix trees and k-means.
YOLO For Firearm Localization and Classification
YOLO For Firearm Localization and Classification
Using YOLOv11 to detect firearms, part of my published research on object detection.
Understand Website AWS Lambda Backend
python
import json
import boto3
from typing import List, Dict, Any
import os
from datetime import datetime
import time
from huggingface_hub import InferenceClient
# AWS clients
s3_client = boto3.client('s3')
# Environment variables
HF_API_TOKEN = os.environ.get('HUGGINGFACE_API_TOKEN') # Get from HuggingFace.co
OPENAI_API_KEY = os.environ.get('OPENAI_API_KEY')
S3_BUCKET = os.environ.get('S3_BUCKET_NAME')
client = InferenceClient(token=HF_API_TOKEN)
# HuggingFace Model Endpoints (Free Inference Client API)
HF_MODELS = {
'embeddings': 'sentence-transformers/all-MiniLM-L6-v2',
'sentiment': 'distilbert/distilbert-base-uncased-finetuned-sst-2-english',
'emotion': 'j-hartmann/emotion-english-distilroberta-base',
'summary': 'openai/gpt-oss-20b'
}
def lambda_handler(event, context):
"""
Main Lambda handler for social media sentiment analysis
Budget-optimized version using HuggingFace free tier
"""
try:
# Parse request
body = json.loads(event['body']) if isinstance(event.get('body'), str) else event.get('body', {})
topic = body.get('topic', 'Machine Learning')
print(topic)
# Step 1: Fetch social media data (using mock data for now)
social_data = fetch_social_media_data(topic)
if not social_data:
return {
'statusCode': 400,
'headers': {'Content-Type': 'application/json'},
'body': json.dumps({'error': 'No data found for topic'})
}
print("Passed achieved social data")
# Step 2: Process with HuggingFace models
results = process_social_data(social_data, topic)
print("Passed process social data")
# Step 3: Store results in S3 with expiration
if S3_BUCKET:
result_key = f"results/{context.aws_request_id}.json"
s3_client.put_object(
Bucket=S3_BUCKET,
Key=result_key,
Body=json.dumps(results),
Metadata={'expires': str(int(time.time()) + 86400)} # 24 hours
)
print("Passed s3")
return {
'statusCode': 200,
'headers': {
'Content-Type': 'application/json',
'Access-Control-Allow-Origin': '*',
'Access-Control-Allow-Methods': 'POST, OPTIONS',
'Access-Control-Allow-Headers': 'Content-Type'
},
'body': json.dumps(results)
}
except Exception as e:
print(f"Error: {str(e)}")
return {
'statusCode': 500,
'headers': {'Content-Type': 'application/json'},
'body': json.dumps({'error': f'Processing failed: {str(e)}'})
}
def call_huggingface_api(model_name: str, inputs: Any, retry_count: int = 3, model_type: str = 'sentiment') -> Dict:
"""
Call HuggingFace Inference API with retry logic
Free tier: 30,000 requests/month
"""
if model_type == 'sentiment' or model_type == 'emotion':
results = client.text_classification(text=inputs, model=model_name)
return results
elif model_type == 'embeddings':
results = client.feature_extraction(text=inputs, model=model_name)
return results
else: # summary
results = client.chat.completions.create(
model=model_name,
messages=[
{
"role": "user",
"content": inputs
}
],
)
result = results.choices[0].message
return result['content']
def fetch_social_media_data(topic: str) -> List[Dict]:
"""
Mock social media data for testing
In production, implement actual API calls or use webhooks
"""
# For testing, return mock data
mock_data = [
{
'text': f"Really excited about the latest developments in {topic}! Game-changing stuff.",
'source': 'twitter',
'timestamp': datetime.now().isoformat()
},
{
'text': f"I've been working with {topic} for years, and this is revolutionary.",
'source': 'reddit',
'timestamp': datetime.now().isoformat()
},
{
'text': f"Not sure about all the hype around {topic}. Seems overrated to me.",
'source': 'linkedin',
'timestamp': datetime.now().isoformat()
},
{
'text': f"Just published my thoughts on {topic}. Check out my latest blog post!",
'source': 'bluesky',
'timestamp': datetime.now().isoformat()
},
{
'text': f"Breaking: Major company announces {topic} integration in their products.",
'source': 'news',
'timestamp': datetime.now().isoformat()
}
]
return mock_data
def process_social_data(social_data: List[Dict], topic: str) -> Dict[str, Any]:
"""
Process using HuggingFace free tier APIs
"""
# Initialize results
results = {
"count": len(social_data),
"emoInt": 0.0,
"emoPos": 0.0,
"sites": {
"reddit": 0,
"linkedin": 0,
"twitter": 0,
"bluesky": 0,
"news": 0
},
"excerpts": [],
"takeaways": [],
"summary": "",
"conclusion": "",
"data": social_data
}
if not social_data:
return results
# Process each text
texts = [item['text'] for item in social_data]
sources = [item['source'] for item in social_data]
# Step 2: Get sentiment scores
sentiment_scores = []
emotion_scores = []
for i, text in enumerate(texts[:10]): # Process first 10 to stay in free tier
# Count by source
source = social_data[i]['source']
if source in results["sites"]:
results["sites"][source] += 1
# Get sentiment
try:
sentiment = get_sentiment_score(text)
sentiment_scores.append(sentiment)
except Exception as e:
print(f"Sentiment failed for text {i}: {e}")
sentiment_scores.append(0.5)
# Get emotion intensity
try:
emotion = get_emotion_intensity(text)
emotion_scores.append(emotion)
except Exception as e:
print(f"Emotion failed for text {i}: {e}")
emotion_scores.append(0.5)
# Small delay to avoid rate limiting
time.sleep(0.1)
# Calculate averages
def calculate_mean(numbers):
if not numbers:
return 0.5
total_sum = sum(numbers)
total_length = len(numbers)
mean_value = total_sum / total_length
return mean_value
results["emoPos"] = calculate_mean(sentiment_scores)
results["emoInt"] = calculate_mean(emotion_scores)
# Step 3: Select key excerpts (simple selection without vector DB)
query = f"Extract diverse texts relevant to the topic of {topic}."
try:
excerpts_res, context_res = perform_retrieval(texts, sources, query)
except Exception as e:
print(f"Retrieval failed with this error: {e}")
excerpts_list = [doc.model_dump() for doc in excerpts_res]
results["excerpts"] = excerpts_list
context_list = [doc.page_content for doc in context_res]
# Step 4: Generate summary using OpenAI (optional, only if API key provided)
summary_data = generate_openai_summary(context_list, topic, results["emoPos"], results["emoInt"])
parsed = parse_summary_sections(summary_data=summary_data)
results["summary"] = parsed["summary"]
results["conclusion"] = parsed["conclusion"]
results["takeaways"] = parsed["takeaways"]
return results
def get_sentiment_score(text: str) -> float:
"""
Get sentiment using HuggingFace DistilBERT
"""
try:
result = call_huggingface_api(HF_MODELS['sentiment'], text, model_type='sentiment')
# Parse result (list of dicts with 'label' and 'score')
if isinstance(result, list) and len(result) > 0:
item = result[0] # result[0] contains the predictions
if item['label'] == 'POSITIVE':
return item['score']
elif item['label'] == 'NEGATIVE':
return 1.0 - item['score']
return 0.5 # Neutral fallback
except Exception as e:
print(f"Sentiment analysis failed: {e}")
return 0.5
def get_emotion_intensity(text: str) -> float:
"""
Get emotion intensity using HuggingFace emotion model
Maps emotions to intensity scores
"""
try:
result = call_huggingface_api(HF_MODELS['emotion'], text, model_type='emotion')
# Map emotions to intensity (0-1 scale)
emotion_intensity_map = {
'anger': 0.9,
'disgust': 0.8,
'fear': 0.85,
'joy': 0.7,
'sadness': 0.75,
'surprise': 0.6,
'neutral': 0.2
}
if isinstance(result, list) and len(result) > 0:
# Get the highest scoring emotion
#top_emotion = max(result[0], key=lambda x: x['score'])
top_emotion = result[0]
emotion_label = top_emotion['label'].lower()
confidence = top_emotion['score']
# Calculate intensity based on emotion type and confidence
base_intensity = emotion_intensity_map.get(emotion_label, 0.5)
return base_intensity * confidence
return 0.5
except Exception as e:
print(f"Emotion analysis failed: {e}")
return 0.5
from langchain_core.embeddings import Embeddings
class CustomAPIEmbeddings(Embeddings):
def embed_documents(self, texts: List[str]) -> List[List[float]]:
return call_huggingface_api(HF_MODELS['embeddings'], texts, model_type='embeddings')
def embed_query(self, text: str) -> List[float]:
return call_huggingface_api(HF_MODELS['embeddings'], text, model_type='embeddings')
def perform_retrieval(texts: List[str], sources: List[str], query: str, k: int = 2, fetch_k: int = 20):
from langchain.docstore.document import Document
from langchain_community.vectorstores import FAISS
docs = [
Document(
page_content=text,
metadata={'source' : source}
) for text, source in zip(texts, sources)
]
custom_embedder = CustomAPIEmbeddings()
vectorstore = FAISS.from_documents(
documents=docs,
embedding=custom_embedder
)
excerpts_res = vectorstore.max_marginal_relevance_search(
query=query,
k=k,
fetch_k=fetch_k if fetch_k < len(texts) else len(texts),
lambda_mult=0.7
)
context_res = vectorstore.max_marginal_relevance_search(
query=query,
k=(k + 12) if k + 12 < len(texts) else len(texts),
fetch_k=fetch_k if fetch_k > len(texts) else len(texts),
lambda_mult=0.7
)
return excerpts_res, context_res
def generate_openai_summary(texts: List[str], topic: str, emo_pos: float, emo_int: float) -> Dict[str, Any]:
"""
Generate summary using OpenAI GPT20B OSS Off Huggingface, which should be included in the 30000 requests
"""
context = "
".join(texts) # Use top 5 texts only
prompt = f"""Analyze social media sentiment about {topic}. Speak in a friendly, lively manner.
Emotional Positivity: {emo_pos * 100:.1f}%
Emotional Intensity: {emo_int * 100:.1f}%
Sample posts:
{context[:1500]}
Provide:
1. One paragraph summary
2. One paragraph conclusion
3. Two key takeaways with bullet points"""
return call_huggingface_api(HF_MODELS['summary'], prompt, model_type='summary')
def parse_summary_sections(summary_data: str) -> Dict[str, str]:
"""
Extract summary, conclusion, and key takeaways from the AI response
Handles various formats: **Bold**, ###Headers, bullet points, etc.
"""
import re
# Initialize results
sections = {
"summary": "",
"conclusion": "",
"takeaways": ""
}
# Normalize the text (in case of weird spacing)
text = summary_data.strip()
# Pattern to match section headers (flexible)
# Matches: **Summary**, ### Summary, Summary:, SUMMARY, etc.
summary_pattern = r'(?:^|
)(?:*{2,}|#{1,3}s*)?(?:Summary|SUMMARY|Overview|Introduction)(?:*{2,}|:)?(?:s*
+)(.*?)(?=
(?:*{2,}|#{1,3}s*)?(?:Conclusion|Keys*Takeaway|Takeaway|CONCLUSION|KEY)|Z)'
conclusion_pattern = r'(?:^|
)(?:*{2,}|#{1,3}s*)?(?:Conclusion|CONCLUSION|Finals*Thoughts?)(?:*{2,}|:)?(?:s*
+)(.*?)(?=
(?:*{2,}|#{1,3}s*)?(?:Keys*Takeaway|Takeaway|KEY|Recommendation)|Z)'
takeaways_pattern = r'(?:^|
)(?:*{2,}|#{1,3}s*)?(?:Keys*Takeaways?|Takeaways?|KEYs*TAKEAWAYS?|Recommendations?)(?:*{2,}|:)?(?:s*
+)(.*?)(?:Z)'
# Extract each section
summary_match = re.search(summary_pattern, text, re.DOTALL | re.IGNORECASE)
if summary_match:
sections["summary"] = summary_match.group(1).strip()
conclusion_match = re.search(conclusion_pattern, text, re.DOTALL | re.IGNORECASE)
if conclusion_match:
sections["conclusion"] = conclusion_match.group(1).strip()
takeaways_match = re.search(takeaways_pattern, text, re.DOTALL | re.IGNORECASE)
if takeaways_match:
# Clean up takeaways - remove extra bullet formatting if needed
takeaways_text = takeaways_match.group(1).strip()
# Keep bullet points but clean them up
takeaways_text = re.sub(r'^[-•*]s*', '• ', takeaways_text, flags=re.MULTILINE)
sections["takeaways"] = takeaways_text
# Fallback: If no headers found, split by paragraphs
if not any(sections.values()):
paragraphs = [p.strip() for p in text.split('
') if p.strip()]
if len(paragraphs) >= 1:
sections["summary"] = paragraphs[0]
if len(paragraphs) >= 2:
sections["conclusion"] = paragraphs[1]
if len(paragraphs) >= 3:
# Join remaining paragraphs as takeaways
sections["takeaways"] = '
'.join(paragraphs[2:])
return sections
Understand Website AWS Lambda Backend
Using GPT-OSS 20B, embedding, sentiment, and intensity models from hugging face API for maximal marginal retrieval, for understanding public opinions.